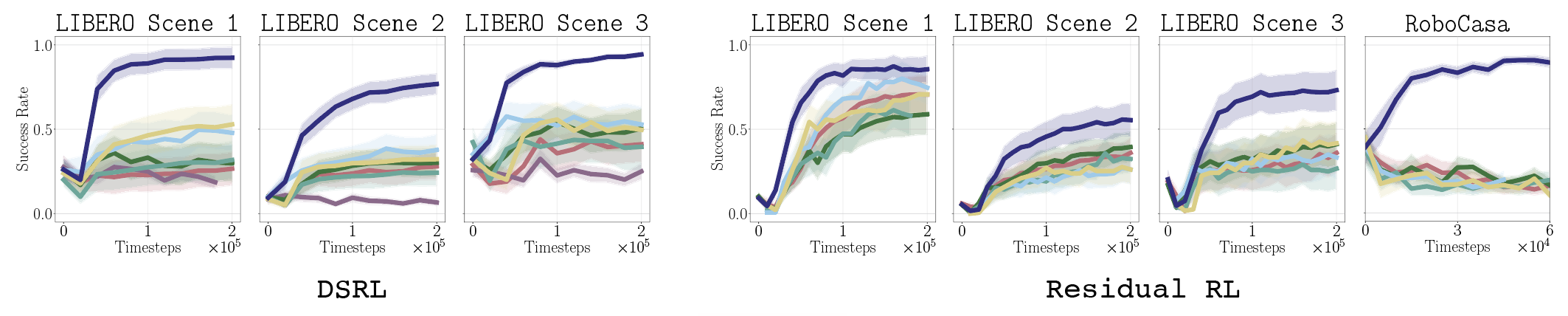
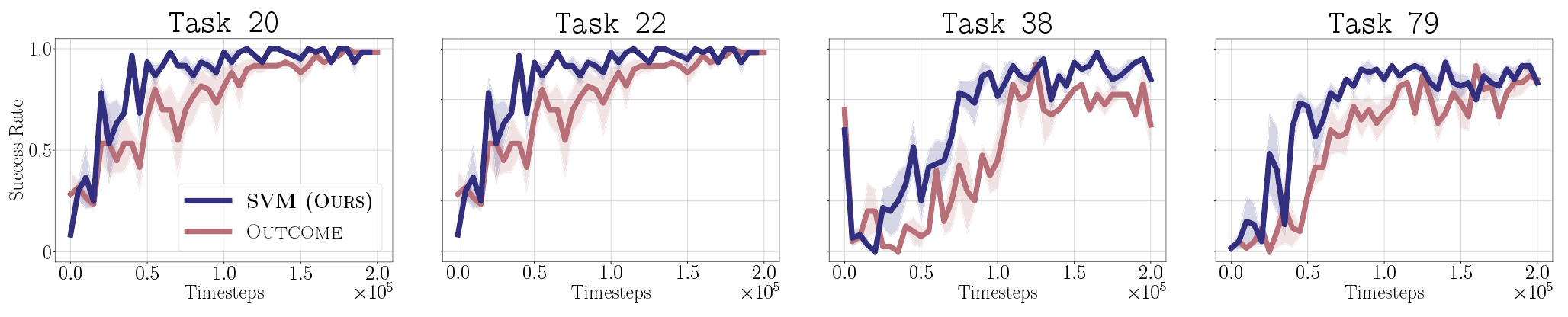
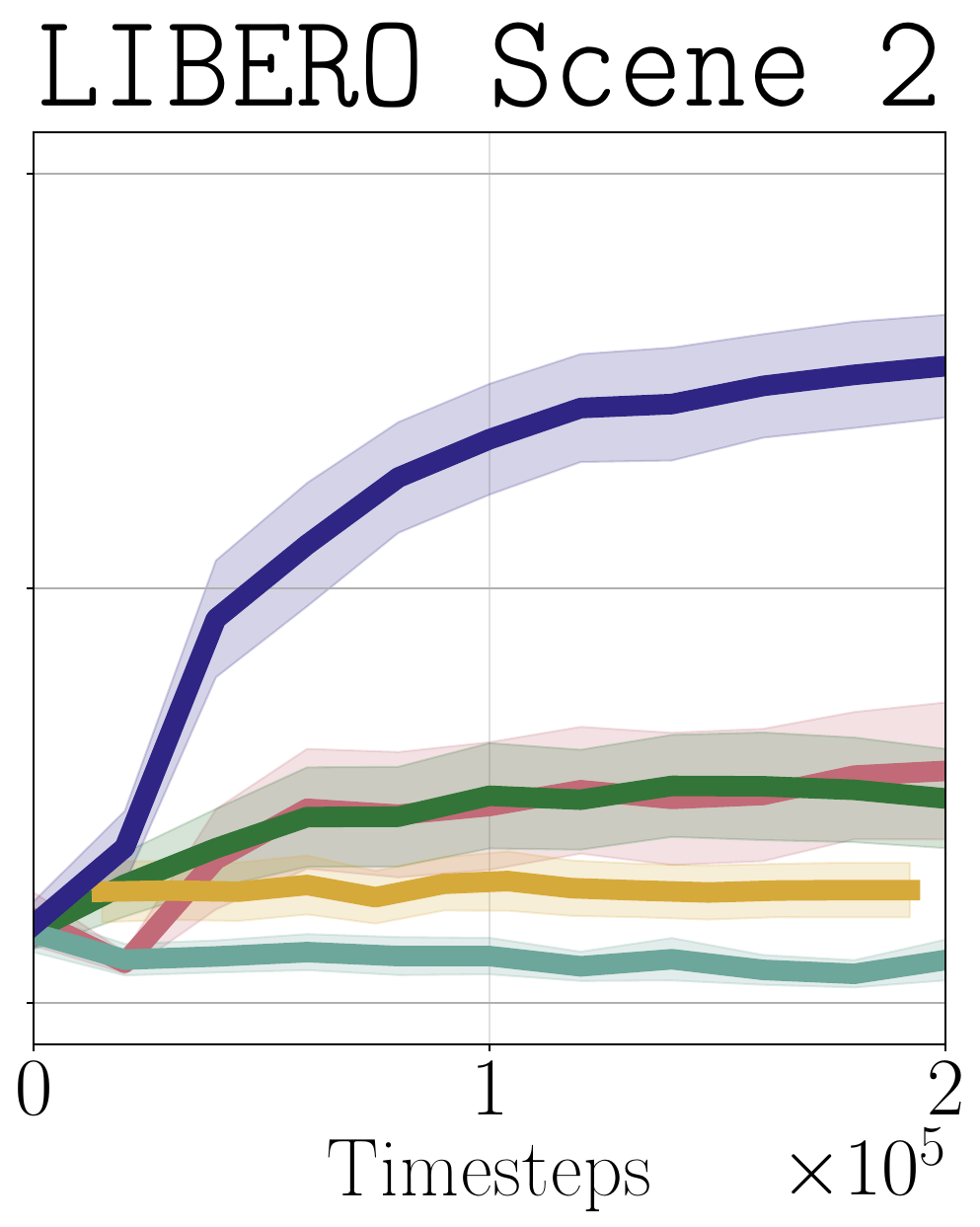
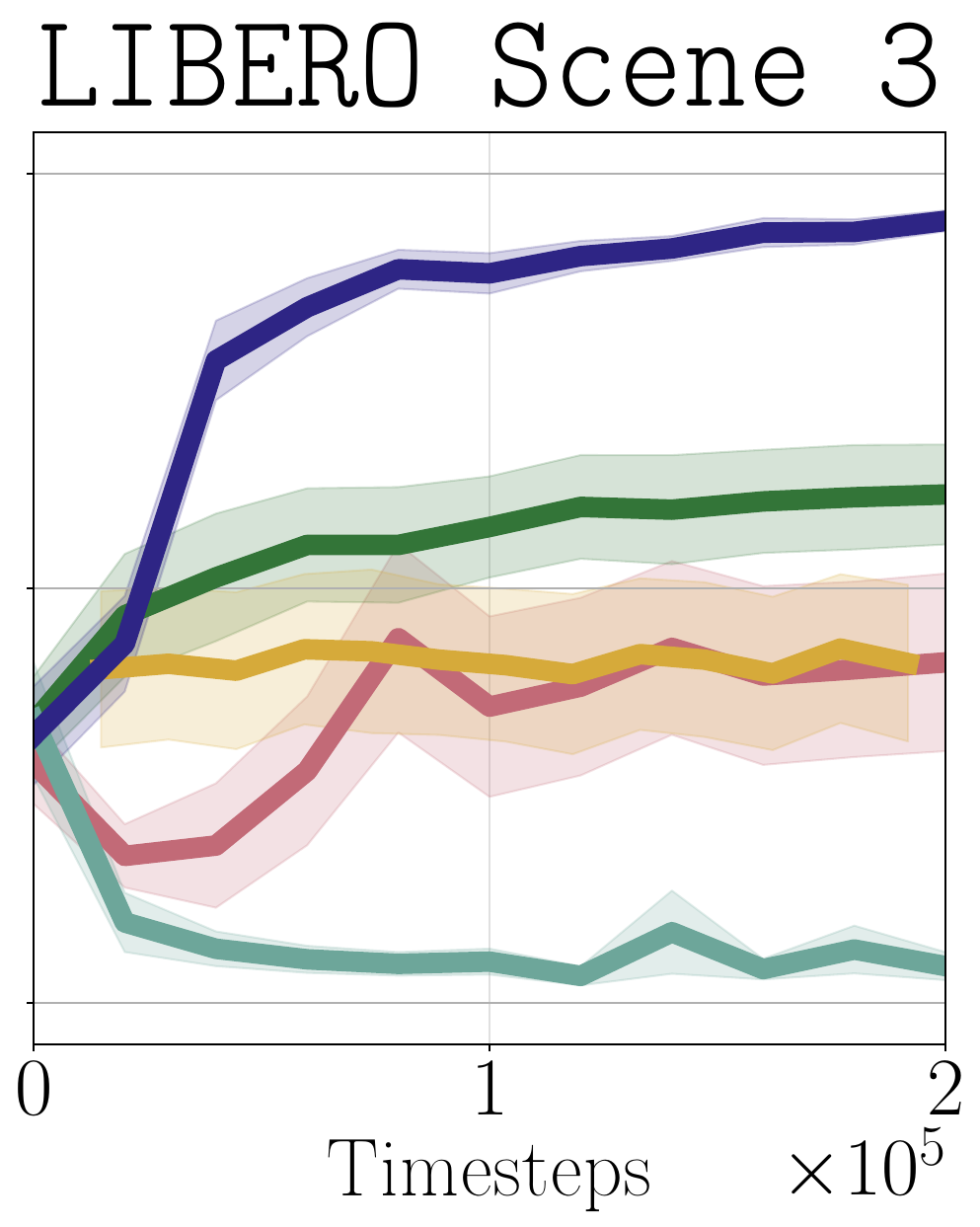
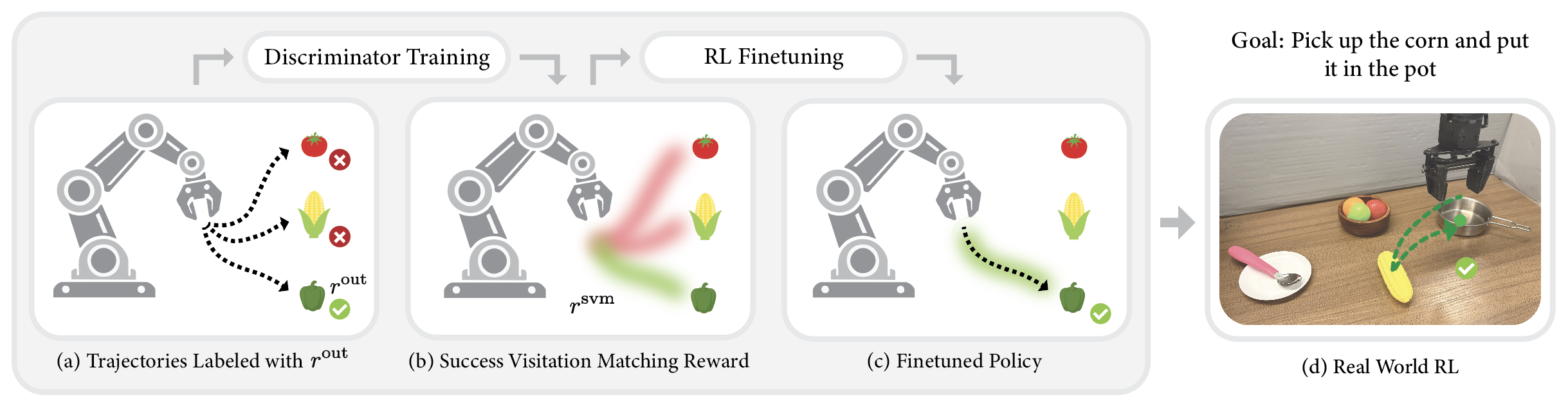
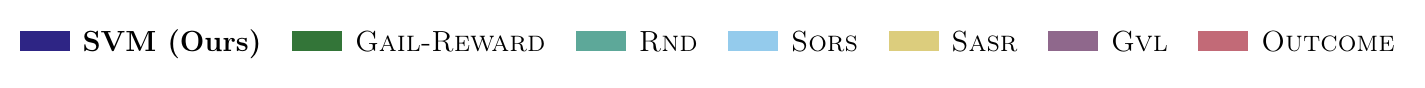Method
We consider the problem of finetuning a pretrained policy $\pi_{\text{pre}}$ to maximize a sparse outcome reward $r^{\mathrm{out}}$. To enable efficient RL finetuning, we seek to design a dense process reward that:
(a) Provides dense step-level feedback guiding the learner toward successful states, and
(b) Peserves the optimal policies under the original outcome reward.
Our approach is based on a simple principle: given past episodes labeled by outcome reward $r^{\mathrm{out}}$, reward the learner for visiting state-actions that are associated with successful episodes, and penalize those associated with unsuccessful episodes. Concretely, denoting $\mathfrak{D}^+$ and $\mathfrak{D}^-$ the state-action pairs from successful and unsuccessful episodes, respectively, we train a discriminator to distinguish these two sets: $$\widehat{f}(s,a) = {\text{argmin}_{f}}\; \mathbb{E}_{(s, a)\sim \mathfrak{D}^+} [\log f(s,a)]+ \mathbb{E}_{(s, a)\sim \mathfrak{D}^-}[\log (1-f(s,a))]$$ We then define the success visitation matching (SVM) process reward with the discriminator logit: $$r^{\mathrm{svm}}(s,a)= r^{\mathrm{out}}(s) + \lambda \cdot \mathrm{clip}_\beta \left ( \log \frac{\widehat{f}(s,a)}{1-\widehat{f}(s,a)} \right )$$ where $\mathrm{clip}_\beta(\cdot)$ clips the value to be within the range $[-\beta,\beta]$. This yields a dense process reward that encourages the learner to visit states likely to lead to success based on past observations—states where $\widehat{f}(s,a)$ is large—while balancing this with the true outcome reward. We show the following:
RL Finetuning with SVM Process Rewards
We propose running RL with the SVM process reward, iteratively updating $\widehat{f}$ online as new observations are collected.Algorithm: Reinforcement Learning with SVM Process Reward
- Input: $r^{\mathrm{svm}}$ weight $\lambda$, $r^{\mathrm{svm}}$ clipping $\beta$, pretrained $\pi_{\mathrm{pre}}$ (optional), initial rollouts $N_0$ (optional)
- Collect $N_0$ trajectories with $\pi_{\mathrm{pre}}$, set $\mathcal{D}^+$ to successful trajectories, $\mathcal{D}^-$ to all others
- Initialize discriminator $\widehat{f}$ on $\mathcal{D}^+$ and $\mathcal{D}^-$
- Initialize $\pi_1$ to $\pi_0$ or random policy
- for $t = 1, 2, 3, \ldots$ do
- Run $\pi_t$ for one episode, add trajectory to $\mathcal{D}^+$ if it is successful, otherwise to $\mathcal{D}^-$
- Update $\widehat{f}$ on $\mathcal{D}^+$ and $\mathcal{D}^-$
- Update $\pi_t$ to $\pi_{t+1}$ by maximizing reward $r^{\mathrm{svm}}(s,a) = r^{\mathrm{out}}(s) + \lambda \cdot \mathrm{clip}_\beta\left(\log \frac{\widehat{f}(s,a)}{1-\widehat{f}(s,a)}\right)$
- end for